
Computational science
The SCD Computational Science Section (CSS) provides state-of-the-art
expertise in aspects of computing beneficial to the atmospheric and
oceanic sciences communities. Our efforts are focused on four areas:
We share the results of our work through collaborations, publications,
software development, and seminars.
CSS conducts research in areas such as computational fluid dynamics,
parallel communications algorithms for massively parallel architectures,
and numerical solutions to elliptic partial differentialequations using
multigrid techniques. In addition, we are conducting basic research in
alternate formulations of atmospheric and ocean models based on
triangular (icosahedral) discretizations of the sphere.
The section engages in joint projects with groups within NCAR and from
other institutions and agencies. These projects benefit the broader
NCAR community. Currently, CSS is involved in projects, in conjunction
with the Climate and Global Dynamics (CGD) Division of NCAR, and with
support from the Department of Energy's (DOE) Computer Hardware,
Advanced Mathematics, and Model Physics Project (CHAMMP) initiative,
to develop a state-of-the-art coupled climate model framework that
will run efficiently and effectively on distributed memory parallel
computers. These projects are described below.
CSS is involved in technology tracking (performance monitoring and
benchmarking studies) of both hardware and software. This work
ensures the efficient use of current computing resources and is
critical in selecting the most appropriate computers for the future
production computing needs of NCAR and the university community.
On the software side, staff play an active role in the Fortran
standards effort as well as evaluating programming languages and
paradigms.
We develop software packages to make use of our research results
and our numerical and computational expertise. These libraries of
scientific software are used by researchers in the atmospheric
and related sciences community.
Finally, CSS staff are active in the area of education, outreach,
and knowledge transfer. We process all university requests for
computing resources. We organize workshops, guest-lecture at
universities, host post docs, and give seminars and talks at
conferences.
An efficient spectral transform method for solving
the shallow water equations on the sphere
William F. Spotz, Mark A. Taylor and Paul N. Swarztrauber
have studied the spectral transform method developed by
Merilees in 1973. In that work, the required spatial derivatives are
computed by the formal differentiation of a two-dimensional,
latitude-longitude, Fourier series approximations to both vector and
scalar functions on the surface of the sphere. The time derivatives
are then computed from the shallow water equations in advective form
and the solution is advanced in time using leap frog time
differencing. Stability is maintained using both spatial and time
filters; however, the filters require tuning and the resulting
tradeoff between accuracy and stability made this approach less
attractive than emerging transform methods based on harmonic spectral
approximations. In this paper we replace Merriles' filter with a
harmonic filter consisting of a analysis followed directly by a
synthesis. This provides the homogeneous representation of waves that
is characteristic of traditional spectral methods. The stability and
accuracy of the resulting computations are the same as the harmonic
spectral method. The harmonic filter is applied only to the dependent
functions and consequently the method requires about half the number
of Legendre transforms that are required by the existing spectral
methods. In theory, this approach can be viewed as a fast method since
fast harmonic filters exist in print however they have not yet been
demonstrated in spectral models. Computational examples have been
developed on an equally spaced grid that includes the points at the
poles.
Transposing multiprocessors using de Bruijn sequences
Transposing an NxN array that is distributed row- or column-wise
across P=N processors is a fundamental communication task that
requires time-consuming interprocessor communication. It is the
underlying communication task for matrix-vector multiplication and the
fast Fourier transform (FFT) of long sequences and multi-dimensional
arrays. It is also the key communication task for certain weather and
climate models. Paul N. Swarztrauber has developed a parallel
transposition algorithm for multiprocessors with a programmable
network channels. The optimal scheduling of these channels is
non-trivial and has been the subject of a number of papers. Here,
scheduling is determined by a single de Bruijn sequence of N bits.
The elements are first ordered in each processor and, in
sequence, either transmitted or not transmitted, depending on
the corresponding bit in the de Bruijn sequence. The de Bruijn
sequence is the same for all processors and all communication
cycles. The algorithm is optimal both in the overall time and the time
that any individual element is in the network (span). The results are
extended to other communication tasks including shuffles, bit
reversal, index reversal, and general index-digit permutation. The
case P not equal to N and rectangular arrays with non-power-of-two
dimensions are also discussed. The results are extended to mesh
connected multiprocessors by embedding the hypercube in the mesh. The
optimal implementation of these algorithms requires certain
architectural features that are not currently available in the
marketplace.
MPP: What went wrong? Can it be made right?
In early 1988, NCAR benchmarked the Connection Machine 2 (CM2). A
fully configured machine had 2048 processors and a peak performance of
32 Gflops. A finite difference version of a shallow-water model ran at
1.7 Gflops (5% of peak) and a spectral version ran at 1 Gflop (3% of
peak). Later, a joint project to implement a working massively
parallel processor (MPP) climate model was established with NCAR, Oak
Ridge, Argonne, and Los Alamos. After considerable effort the model
ran at about 7% of peak on the CM5 in 1995. At best, this performance
was comparable to traditional architectures that achieved a much
higher percentage of peak and required less code development
effort. MPP had not lived up to expectations. The origins of the
problem were quite evident. On the CM2, 185 cycles were required for a
memory to memory transfer between adjacent processors compared with a
processor performance of two floating point operations per cycle. The
high cost of this interprocessor communication resulted in a
significant degradation in sustained performance. Similar results
have been reported by NCAR and other institutions for a number of
machines that have come to the market. Paul Swarztrauber presents a
combination of algorithms and hardware features that reduces processor
to processor communication to a single cycle (on average) not only to
an adjacent processor but to the destination processor and in
parallel. If implemented, communication could be reduced by as
much as two orders of magnitude and perhaps the original promise of
MPP could be realized.
Spectral element filters
Spectral viscosity filter
The spectral viscosity method of Tadmor is applied to the spectral
element method. The method applies higher values of the viscosity
to the high wave numbers, thereby stabilizing calculations for
under-resolved fluid mechanics problems. For the Stommel advection
test case of Hecht the method improves the solution's l_infinity
norm, a measure of the loss in tracer magnitude, from about .38 to .70.
Non-linear filter
A non-linear technique reduces, and in some case removes, the need for
the user to choose parameters such as filter order. This technique is
applied to both the erfc-log filter and the spectral viscosity filter.
This is work in progress.
Overflow problems in the ocean
The spectral element method of Iskandarani is applied to the case of
the high density fluid in the Greenland Sea emptying into the warmer,
lower density water of the North Atlantic Ocean. The density difference
is large, and requires higher resolution than climate models currently
allow. This model is run on the HP Exemplar SPP2000 in parallel. This
work is in collaboration with Dale Haidvogel and Mohamed Iskandarani
and Rutgers University.
Stommel advection test case
To facilitate testing of numerical schemes for the ocean, we found
a closed form solution to the hyperbolic advection equation with
variable coefficients. This problem will be included in the
oceanographic test cases of Paluskiewicz, a DOE effort to have a
standardized suite of test cases for testing numerical schemes.
Spectral elements on triangles
Spectral elements applied to quadrilateral domains are inconvenient
for adaptive mesh techniques. One method of doing this uses the
mortar element technique, but it destroys the diagonal mass matrix
enjoyed by conforming methods. The methods of Dubiner. This research
finds the natural eigenfunctions on the triangle.
The Vector Multiprocessor
A patent has been granted on a novel computer design called the
Vector Multiprocessor (VMP) developed by Paul Swarztrauber.
This architecture brings to the multiprocessor what
vectorization brought to the single processor. All vectors and arrays
are uniformly distributed across the processors and additional vectors
that are generated at run time by vector subscript syntax are also
distributed at the average rate of one element per cycle to every
processor. Computation then proceeds independently in each processor
using the parallelism that is implicit in traditional vector
calculations. Granularity ranges from fine-grain elementwise
distribution to traditional coarse-grain computations depending on the
size N of the vectors/arrays and the number of processors P. Each
processor contains N/P elements and the programming paradigm is the
same as a single vector processor. A program written for a single
vector processor ports to the VMP with minimal modification. The VMP
is the product of an effort to determine the optimum algorithmic and
architectural environment for weather/climate models. It is a general
purpose high performance scalable multiprocessor (SMP) that evolved
from the answers to such questions as: What is the best possible SMP
performance? Will communication always dominate SMP performance? Is
there a "best" SMP architecture?
Spectral and high-order methods for the shallow water equations
on the sphere
Research is being conducted on ways of approximating the spatial
derivatives required to solve the shallow water equations on the
sphere which are faster and scale better than the spectral transform
method currently in use. This has led to a revival of Merilees'
pseudospectral method and Gilliland's fourth-order compact method.
Both these methods require filtering to avoid the restrictive CFL
(time-step) condition associated with latitude-longitude grids and
to improve the stability of explicit time-stepping methods. In the
past, sufficiently robust filters could not be found and the methods
were abandoned.
We have found a robust and stable, albeit slow, filter which uses
spherical harmonics. This filter has demonstrated that any reasonably
accurate method used for spatial derivatives in spherical geometry is
all that is needed, as long as the filter is sufficiently robust.
Thus, the problem reduces to either (1) finding a fast version of the
spherical harmonic filter, or (2) sufficiently emulating the spherical
harmonic filter's stability properties with a more traditional
FFT-based filter. Finding a fast Legendre transform has long proved
elusive, but the fast spherical harmonic filter problem has provided
new opportunities in this area. Similarly, projecting the spherical
harmonic filter response onto FFT-space has helped guide us in
designing new FFT filters, giving us two promising approaches to the
fast filter problem.
SEAM: Spectral Element Atmospheric Model
We have continued the development SEAM, a spectral element atmospheric
model. This is a complete GCM dynamical core which uses a spectral
element discretization in the horizontal direction (the surface of the
sphere) taken from the shallow water model described in [Taylor et al,
J. Comput. Phys. 1997]. Spectral elements are a type of finite
element method in which a high degree spectral method is used within
each element. The method provides spectral accuracy while retaining
both parallel efficiency and the geometric flexibility of unstructured
finite elements grids. In the vertical direction, SEAM makes use of a
sigma coordinate finite difference discretization taken from the NCAR
CCM3 [Kiehl et al. NCAR/TN-420+STR, 1996]. We are conducting research
in four areas related to SEAM:
1. Performance on NCAR's HP Exemplar
Spectral element methods are ideal for modern MPPs. Standard domain
decomposition software is used to distribute the elements among the
processors. Communication costs are minimal since each element needs
only to communicate its boundary data with neighboring elements. The
computationally intensive spectral transforms which must be performed
within each element are localized to each processor and require no
communication. Furthermore, the elements in the spectral element
method provide a natural way to block the code, providing an
additional advantage: lots of computations are performed on small
blocks of data which fit into the cache of the processor. Unlike
spherical harmonic spectral methods, the size of these blocks in the
spectral element method is small and independent of resolution. Thus
we have good performance and scalability even at resolutions above T85
where global spectral models start to experience cache "thrashing."
On NCAR's HP Exemplar, for a wide variety of problem and machine
sizes, SEAM has close to perfect scalability up to 64 processors. For
example, a T85/L20 test case runs at between 100 and 130 MFLOPS per
processor, all the way up to 64 processors. This gives us a sustained
performance of 9 GFLOPS on the full machine. Preliminary results
suggest that we will be able to achieve 25 GFLOPS on a 256 processor
HP Exemplar.
2. Validation of the model
In addition to achieving impressive GFLOP rates, any numerical model
must of course also produce accurate results. We have been making
extensive use of the Held-Suarez dry dynamical core test case [Held
and Suarez, Bull. Amer. Met. Soc. 1994] to validate SEAM and compare
SEAM with other GCM dynamical cores. The results are practically
identical to Held-Suarez results from spherical harmonic spectral
models.
3. Localized mesh refinement
SEAM makes use of fully unstructured grids, allowing a single low
resolution grid to contain areas of higher horizontal resolution.
Thus regional and higher resolution can be achieved (over a limited
region) within a global model in a truly interactive fashion and
without resorting to any kind of a posteriori nesting or interpolation
between different models. This work may lean to improved climate
simulations by allowing increased resolution in a few dynamically
significant regions. Similarly, regional climate simulations may be
improved by allowing regional resolution to be incorporated within a
global model in a two-way interactive fashion. We have demonstrated
the effectiveness of this type of localized mesh refinement in the
shallow water equations. We are now in the process of testing the
effectiveness of local mesh refinement using the full 3D primitive
equations. We are using the Held-Suarez test case forcing along with
realistic topography. As expected, the vertical velocity has
unrealistically large Gibbs-like oscillations upstream of steep
topography. We have recently completed a suite of long integrations
at various uniform global resolutions. These will soon be followed
with runs made with very high resolution only near the Andes and the
Himalayas and uniform, lower resolution over the rest of the sphere.
We expect these results to be similar to those obtained with the
shallow water equations: Improved solutions at significantly less
computational cost.
4. SEAM vs. CCM3
At present SEAM uses an explicit time step which is 8 times smaller
than that used in conventional semi-implicit climate models such as
the CCM3. Even with this performance penalty the model runs so
efficiently on MPPs that it is still slightly faster than spherical
harmonic based models. T42/L20 resolution runs at 8s/model day,
compared to about 15s/model day for the dynamical core of CCM3 on
NCAR's HP Exemplar. However, these differences are not that
significant considering that the dynamical core represents less than
50% of work done in a full featured climate model. Thus replacing the
dynamical core of CCM3 with any other model will not result in any
significant performance improvements and will only create many new
problems. Instead, we compare SEAM with CCM3 to establish that SEAM
is a reasonable and competitive GCM dynamical core, with some
disadvantages but also some advantages (such as described in #3 above)
not found in other climate models.
The Computational Science Section (CSS) has responsibility for tracking
the developments in high performance computing technology for SCD
and NCAR. CSS staff assess the capabilities of the latest systems
available from vendors and evaluate the performance of these these
systems on problems typically found in the atmospheric sciences
community. These systems, from workstations to supercomputers,
are evaluated through literature, vendor presentations, and benchmarks.
With the exceptions of the shallow water model (SWM) codes, the
benchmark codes are benchmarks which were developed for evaluation
of systems which were proposed in response to the recent UCAR/NCAR
ACE Request for Proposal (RFP). These benchmarks were developed to
represent the NCAR computing workload.
Description of benchmarks
The NCAR benchmark codes are organized into three sets of benchmarks:
the kernel benchmarks, the shallow water model, and the NCAR CCM2
climate model. The complete set is available through anonymous ftp
and descriptions of the benchmarks are given in README files for each
code. (The codes are in the UCAR ftp site,
ftp.ucar.edu/css/,
as kern1.tar.Z, SHAL.tar.Z, and ccm2.t42.tar.Z. The files are
compressed and tarred.)
The kernels are a set of relatively simple codes which measure important
aspects of the system such as cpu speed, memory bandwidth, and
efficiency of intrinsic functions. These are the kernel codes:
- ELEFUNT: elementary function test
- PARANOIA: arithmetic operation test
- IA: indirect addressing speed
- XPOSE: array transpose
- COPY: memory to memory test
- RFFT: "scalar" FFT test
- VFFT: "vectorized" FFT
- RADABS: processor performance
- I/O: memory to disk
The second benchmark set consists of different implementations and
resolutions of a shallow water model. The shallow water equations
give a primitive but useful representation of the dynamics of the
atmosphere. The model has been used over the past decade to evaluate
the high-end performance of computer systems. Finite difference
approximations are used to solve the set of two-dimensional, partial
differential equations. There is a single-processor version (with
Cray multitasking directives), a parallel PVM version, and a Fortran
90 version of the model. The model is easily vectorized and
parallelized and gives an indication of the higher-end performance
of a system for moderate (64 x 64) and high (256 x 256) resolution
problems.
The third benchmark is the NCAR Community Climate Model Version 2
(CCM2), which is a three-dimensional global climate model. This is
the production version of the CCM in early 1994 and is computationally
very close to the current production version which is widely used by
the climate research community.
Systems tested
The current benchmark set was run on the systems in this table during
the past year:
| Systems benchmarked in
1997
|
|
| System
| Model
| Clock
(MHz)
| Peak
(MFLOPS)
|
| CRI
| C90
| 250
| 1000
|
| CRI
| J90/SE
| 100
| 200
|
| HP/Convex
| SPP2000
(PA8000)
| 180
| 720
|
| SGI
| Power
Challenge
(R10000)
| 196
| 392
|
| SUN
| Ultra
Sparc2
| 250
| 500
|
The first figure below shows the performance of these systems for the
computational benchmarks shal64, shal256, and radabs. The next figure
gives
the time to complete one day of simulation of the CCM2 on one processor
of
the systems. The third figure shows a comparison of the memory bandwidth
of
the systems for a copy of an array to a second array.
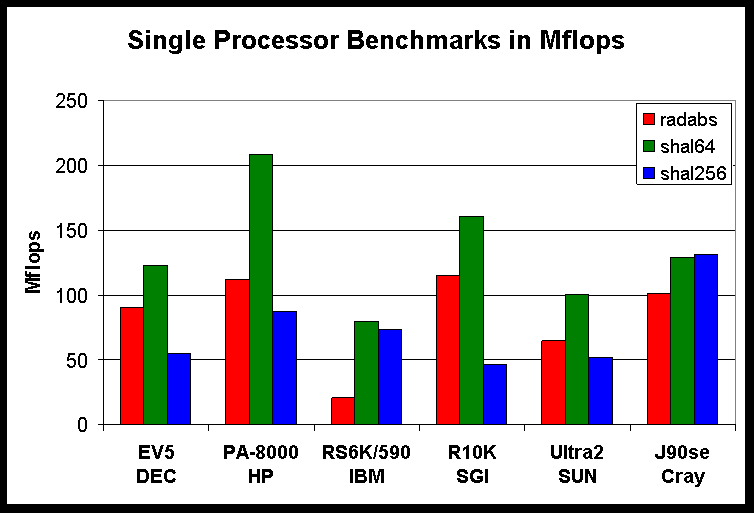
Bar chart showing the performance of radabs, shal64, and
shal256 for each vendor
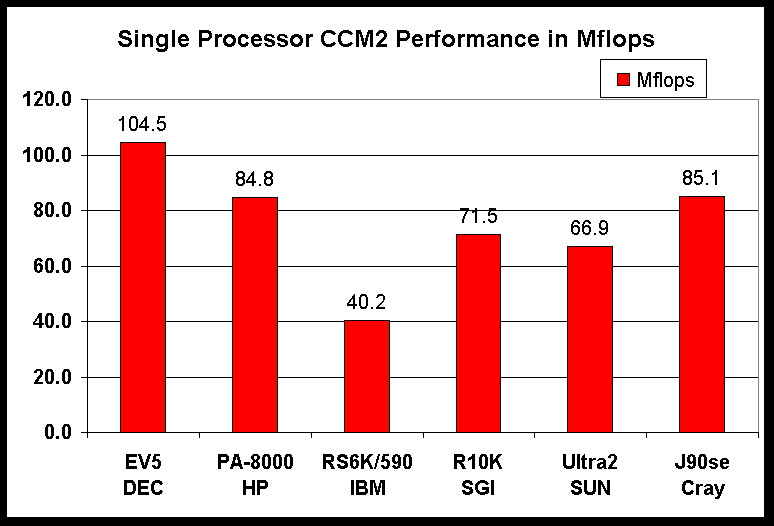
Bar chart showing the performance of CCM2
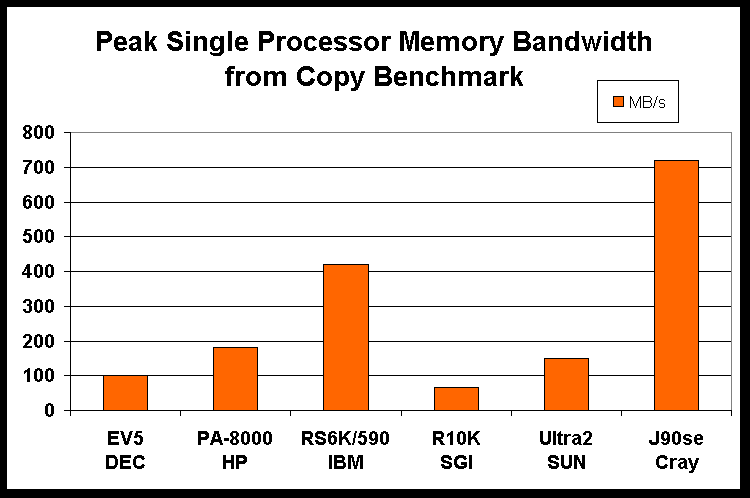
Plot showing the results of the COPY benchmark
Note that the computational performance in MFLOPS increases with
resolution for vector machines but decreases for cache-based
microprocessors. This can be attributed to the performance of
the cache-based memory system of the RISC processors. As problem
size increases, the cache use is less efficient. Figure 3 shows
the memory bandwidth of the systems for the simple task of
copying an array from one memory location to another. For raw
performance, as measured by these benchmarks, for systems with
comparable clock speeds, the vector architectures give better
performance than the RISC microprocessors. However the price
performance of the RISC-based systems is typically better than
that of the vector-processor-based systems.
CSS staff continued to interact with SRC Computers (Seymour Cray's
company in Colorado Springs, CO). SRC personnel have visited
NCAR/SCD on several occasions during the past year to give
non-disclosure presentations on their development efforts and
status. CSS has run a portion of the NCAR benchmarks on the SRC
pre-prototype system and has provided SRC with the NCAR benchmarks
and latest versions of the NCAR atmospheric (CCM3) and ocean
(POP and NCOM) models.
MUDPACK
National and international distribution continues. Last year
36 people from foreign and U.S. institutions received MUDPACK
consultation and software. Plans are underway to (a) create a
Fortran 90 version of the package (b) convert all solvers for
non-singular PDEs to hybrids using direct methods at the coarsest
grid level (c) investigate recoding of relaxation and residual
restriction kernels for efficient implementation on DSM machines.
SPHEREPACK
A Fortran BETA test version of SPHEREPACK 2.0 is now being released
to friendly users. An agreement with Paul White at UCAR has been
reached which specifies conditions for release of the software.
The NCAR technical note "SPHEREPACK 2.0: A MODEL DEVELOPMENT FACILITY"
has been published. Web based documentation is being produced. A
paper is being submitted to the Monthly Weather Review. The package
now consists of 85 main subroutines for computing and inverting
differential operators on the sphere, transferring scalar and vector
fields between Gaussian and equally spaced grids, computing associated
Legendre functions, Gaussian weights and points, multiple fast Fourier
transforms, and display of scalar functions on the sphere. All the
driver-level routines are based on vector and scalar spherical
harmonics. SPHEREPACK 2.0 is being incorporated into the CSM processor
for computation and display of vector and scalar quantities on the
globe.
REGRIDPACK
The original TLCPACK was converted to a fortran 90 compatible version
now called REGRIDPACK. This package "regrids" or transfers data
between higher dimensional grids using vectorized linear or cubic
interpolation. For portability, all codes have been tested on different
platforms with both Fortran 77 and Fortran 90 compilers.
CHAMMP Parallel/Distributed Coupled Modeling
The CSS work on the collaborative Parallel Climate Model (PCM) project
with CGD is focused primarily on porting and optimizing the PCM
components for MPI platforms; particularly, the HP/Convex Exemplar,
the SGI Origin and the Cray T3E. The model consists of three components
(CCM3, POP and ICE) which can be run independently in stand alone mode
for verification, or together with the flux coupler (FCD) in coupled
mode. The source code for each component resides in a shared CVS
repository so that the CGD PCM group and the CSS group can develop
the model concurrently using the same code base.
The MPI port of the CCM3.2 atmosphere model is complete and has been
validated. Most of the communication algorithms were redesigned to
obtain better scaling on 32 or more processors, while maintaining the
ability to run on arbitrary numbers of processors. The decomposition
of the domain by latitude, however, limits the current version of CCM
to no more than 64 processors for T42. The MPI version of CCM3.2
attains more than 2GF/sec on a 64 node HP SPP-2000.
The "new" POP ocean model, written in F90, is maintained by LANL. Since
POP already supports an MPI version, the port to the HP/Convex Exemplar
was fairly simple. However, the performance of POP on the Exemplar was
disappointing compared to the SGI Origin and Cray T3E. A detailed
analysis of the performance of POP on the Exemplar was performed which
pointed to the HP F90 compiler as the problem; specifically, array
section subroutine argument evaluation and array syntax inefficiencies.
A simple test case of POP was translated to F77 using VAST-90 and a
speedup of 3X was obtained, demonstrating that POP could indeed perform
well on the Exemplar hardware. The "new" POP model has been validated
by the CGD PCM group.
The PCM ice model ICE has been ported from a T3D version using the
proprietary Cray "SHMEM" message-passing API to a portable MPI
implementation. Most of the communication algorithms were redesigned
to be more efficient on DSM architectures under MPI. Portability
issues involving default integer size and binary file formats between
the T3D and other platforms were also addressed. The ICE model has
been validated in stand alone mode on the HP SPP-2000, Cray T3E,
and SGI Origin.
The flux coupler FCD was also ported from a T3D "SHMEM" version to a
portable MPI version. Again, many of the communication algorithms were
redesigned to be more efficient on DSM/MPI platforms. The validation
of the flux coupler will be performed when we run the PCM together
in coupled mode.
In the past year, CSS received 149 requests for 50,271.7 General
Accounting Units (GAUs) and sent them out for review. In addition, we
processed 21 requests requiring panel action for use of the Climate
Simulation Laboratory resources totalling 20,379 equivalent C-90 hours.
The panel allocated 10,783 to Antero (C90), 2,600 to the J-9, and
1,395 to the Cray T3D.
In December, 1996, CSS began researching ways to automate the procedure
for processing computing requests, by developing websites and using
existing resources (i.e., oracle databases to simplify report production
and automatically generate expiration or overdrawn status notification
letters to users).
Concurrently, the process was examined to determine ways to streamline
existing procedures to eliminate the duplication of efforts and the use
of outdated methods.
Websites were developed and the first electronic computing request was
received mid-January 1997. Approximately 52% of requests received are
sent to CSS electronically, and since May 20, 1997, all reviews of these
requests have been solicited from potential reviewers electronically.
| Next
page |
Top of this
section |
Table of
contents |
| NCAR |
UCAR |
NSF |
NCAR FY97 ASR |